Abstract
Names are essential to both human cognition and vision-language models. Open-vocabulary models utilize class names as text prompts to generalize to categories unseen during training. However, name qualities are often overlooked and lack sufficient precision in existing datasets. In this paper, we address this underexplored problem by presenting a framework for ``renovating'' names in open-vocabulary segmentation benchmarks (RENOVATE).
Through human study, we demonstrate that the names generated by our model are more precise descriptions of the visual segments and hence enhance the quality of existing datasets by means of simple renaming. We further demonstrate that using our renovated names enables training of stronger open-vocabulary segmentation models. Using open-vocabulary segmentation for name quality evaluation, we show that our renovated names lead to up to 16% relative improvement from the original names on various benchmarks across various state-of-the-art models. We provide our code and relabelings for several popular segmentation datasets (ADE20K, Cityscapes, PASCAL Context) to the research community.RENOVATE fixes typical problems of names in current benchmarks



Left: Ground-truth. Middle: Segmentation (Original name). Right: Segmentation (Renovated name).
RENOVATE upgrades existing benchmarks
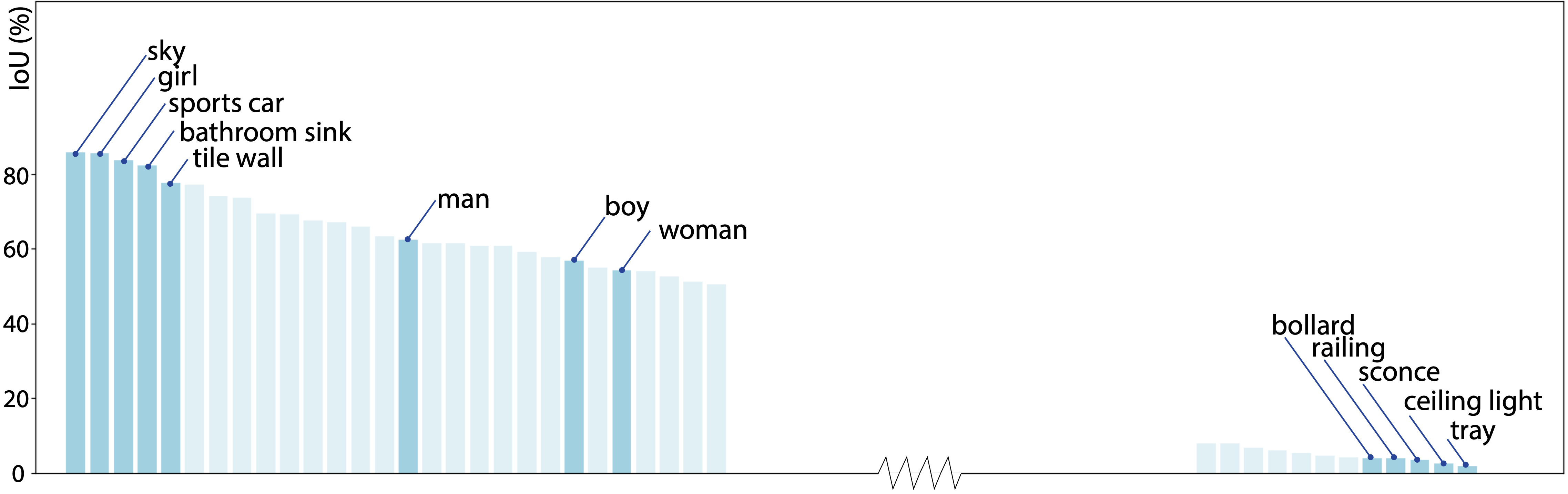
RENOVATE on ADE20K results in 578 classes, allowing us to conduct more fine-grained analysis on open-vocabulary model abilities and biases.
How does it work?
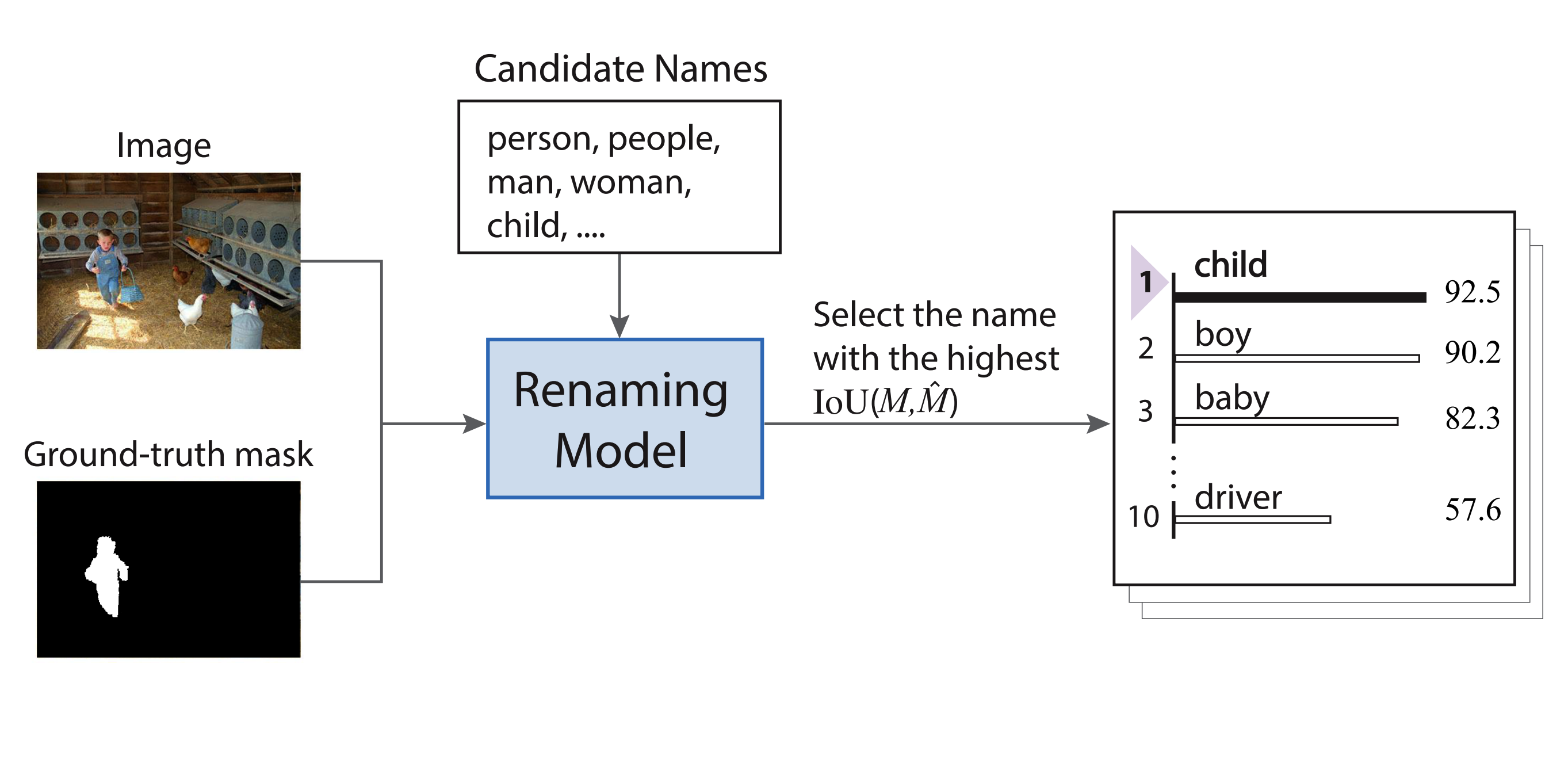
Given the image with the masks and their original names, we use the trained renaming model to rank all the candidate names and obtain a renovated name for each segment.
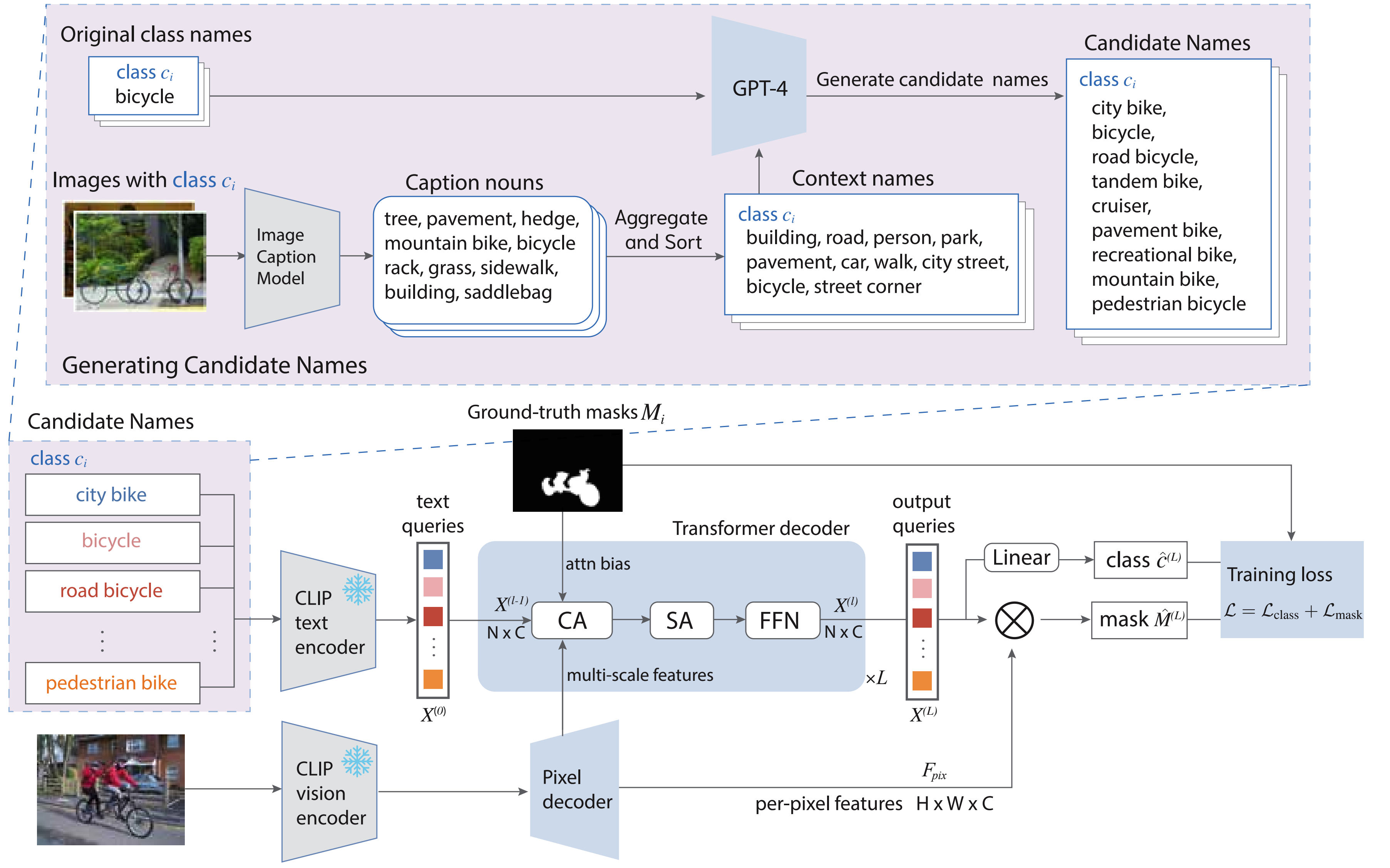
To train our renaming model, we first generate candidate names based on the context names (upper block) and train the renaming model to match them with the segments (lower block). For illustration clarity, we show only one segment. In practice, multiple segments are jointly trained, pairing with the text queries.
More RENOVATE examples





BibTeX
@inproceedings{huang2024renovating,
title={Renovating Names in Open-Vocabulary Segmentation Benchmarks},
author={Haiwen Huang and Songyou Peng and Dan Zhang and Andreas Geiger},
booktitle={The Thirty-eighth Annual Conference on Neural Information Processing Systems},
year={2024},
url={https://openreview.net/forum?id=Uw2eJOI822}
}